 +7 (812) 718-6184
+7 (812) 718-6184
23.05.2017
Цифровая вселенная наполнена данными. Большими Данными. По оценкам специалистов на текущий момент мощность опубликованных в глобальной сети данных составляет 2,7 ЗБайт (Зеттабайт!). Если собрать их в одно хранилище, потребуется небоскрёб для его размещения.
Только за один полёт «Боинг-787» генерирует 500 Гбайт данных, каждую секунду Google обрабатывает 40 тысяч поисковых запросов, то есть в среднем за день порядка 3,5 млрд запросов, а количество абонентов «Мегафона» превысило 77 млн, и для каждого работает система биллинга по множеству показателей. Большие данные пришли в наш мир. Теперь осталось понять, что с ними делать.
Классические системы хранения позволяют нам накапливать информацию, предоставлять к ней доступ по запросу, обрабатывать по указанным шаблонам, не слишком быстро, не легко масштабируемо. Увеличение объёма данных для обработки неизбежно ведёт к увеличению времени в ожидании результата. Причём не линейно, а экспоненциально. Классические СУБД не справляются с Большими Данными. И становится не понятно, как этим богатством распоряжаться.
Существуют три основные проблемы для Больших Данных – как хранить, чем обрабатывать, как обрабатывать. И, конечно, самое важно – кто всё будет делать? Давайте разберёмся.
Большие данные потому и называются большими, что физически занимают очень много места на диске. Хранить их классическим способом в базах данных не удобно и не выгодно, поэтому в экосистеме открытого кода появилось решение в виде платформы Hadoop.
Hadoop представляет собой и систему хранения Hadoop Distributed File System (HDFS), и платформу обработки данных на базе разных движков, например, Map-Reduce. HDFS в рамках кластера организует программно-распределённую систему хранения, доступ к которой организуется через сервер имён (NameNode), а сами данные расположены на подчинённых серверах (DataNode).
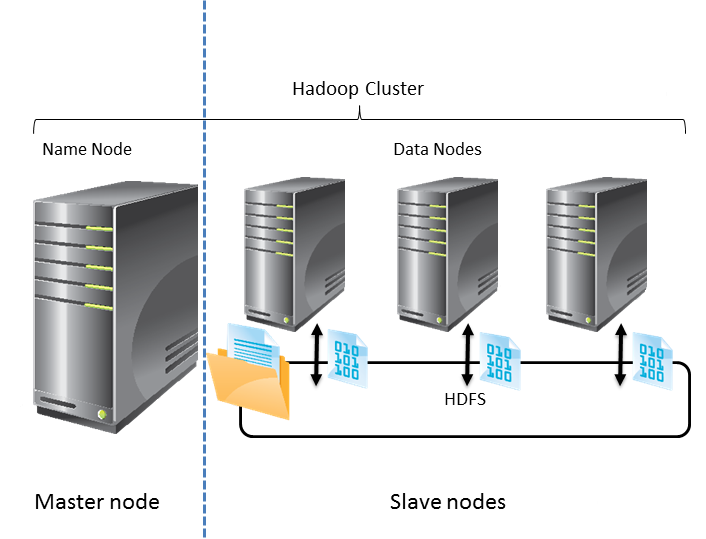
HDFS хранит информацию, где какие данные находятся – путь, список блоков и их реплик. Уникальной HDFS делает тот факт, что сервер имён раскрывает для всех желающих расположение блоков данных на машинах, благодаря чему функцию обработки данных можно выполнять локально, не нагружая сеть процессом передачи данных с сервера хранения на сервер обработки.
Таким образом можно сэкономить время на процессе установки TCP-соединения и выполнять задачи параллельно, повышая эффективность обработки. Именно этим занимается движок Map-Reduce.
Задача обработки данных делится на две части: Map и Reduce. Первая, Map, выполняется параллельно и, в основном, локально над каждым блоком данных. Вместо того, чтобы доставлять терабайты данных к программе, сравнительно небольшая программа копируется на сервера с данными и делает с ними всё, что нужно и не требует перемешивания и перемещения данных. Вторая часть, Reduce, дополняет Map агрегирующими операциями, объединяя и группируя данные. А для оптимизации вычислений, можно использовать Spark, который позволяет хранить промежуточные результаты вычислений не на диске, а в оперативной памяти, что в разы увеличивает производительность.
Итак, есть платформа Apache Hadoop, решающая задачи хранения и реализации вычислений. Половина проблем решена, но осталась вторая половина – как формализовать вычисления, да и кто формализовывать будет? Здесь на сцене появляется Data Scientist – специалист по работе с данными. Именно на плечи этих пионеров обработки данных ложится груз ответственности по написанию логики программы-обработчика, по подготовке правильной структуры данных, которая верно будет обработана программой, и, конечно же, именно эти люди занимаются построением моделей и прогнозированием в среде Больших Данных.
К сожалению, понимание логики работы с Большими Данными пока доступно не всем, но у многих компаний есть огромное желание быть на передовой успеха (а кто владеет информацией – владеет современным миром). Для таких организаций и специалистов компания Microsoft разработала линейку обучающих курсов по работе с Большими Данными.
Первым курсом в линейке представлен 20773 «Анализ Больших Данных с помощью Microsoft R», который расскажет про инструменты обработки Больших Данных, опишет логику работы приложений для Больших Данных и покажет, как интегрировать среду обработки Больших Данных с существующей ИТ-инфраструктурой. Этот курс для разработчиков, админов SQL Server и аналитиков, глубоко разбирающихся в средствах обработки и хранения данных.
Следующий курс 20774 «Облачная аналитика Больших Данных при помощи машинного обучения в Azure». Здесь можно узнать, как без сложной ИТ-инфраструктуры обрабатывать большие данные на серверах в облаке и предоставить результаты вычислений авторизованным пользователям. Курс рассчитан на компании, пока не вложившиеся в свою дорогостоящую инфраструктуру для обработки Больших Данных, а ещё приглядывающиеся и оценивающие – надо или не надо, стоит или не стоит? Чтобы понять – нужно попробовать. И Microsoft предлагает попробовать большие данные на вкус в рамках облака Azure, объясняя в курсе 20774, как воспользоваться инструментами машинного обучения Azure для обработки Больших Данных в облаке.
Для тех, кто понял, что за Большими Данными виднеется большое будущее компании, разработан курс 20775 «Обработка данных с Microsoft HDInsight». Здесь показано, как настроить кластера Hadoop в рамках Microsoft HDInsight, как обслуживать инфраструктуру и устранять неполадки, как настраивать потоковую обработку Больших Данных и создавать интерактивные запросы, а результат визуализировать и предоставлять пользователям. Курс 20775 рассчитан на администраторов, разработчиков и архитекторов систем хранения и обработки Больших Данных.
А для пользователей, желающих ёмко, наглядно и красочно представить результаты обработки Больших Данных подготовлены курсы 20778 «Анализ данных с помощью Power BI» и 20779 «Анализ данных с помощью Excel», решающие задачи визуализации и интерактивного представления данных.
Если перед Вами стоит задача создать интерактивную и информативную экспресс-панель для анализа Больших Данных и разделить доступ к ней со многими участниками с привлечением сервера для публикации – то Вам нужен курс 20778 «Анализ данных с помощью Power BI».
Если Вы пока изучаете возможности интерактивных панелей и задачи ограничиваются предоставлением отчёта в рамках книги Excel, то стоит начать знакомство с миром обработки Больших Данных с курса 20779 «Анализ данных с помощью Excel», рассматривающего возможности настольного приложения Excel 2016 в задачах бизнес-аналитики.
А мы в свою очередь поможем Вам пройти пока не торенной тропой Больших Данных и научим успешно пользоваться передовыми технологиями работы с Большими Данными. Ждём Вас в УЦ «Эврика» на курсах по обработке Больших Данных!
Только за один полёт «Боинг-787» генерирует 500 Гбайт данных, каждую секунду Google обрабатывает 40 тысяч поисковых запросов, то есть в среднем за день порядка 3,5 млрд запросов, а количество абонентов «Мегафона» превысило 77 млн, и для каждого работает система биллинга по множеству показателей. Большие данные пришли в наш мир. Теперь осталось понять, что с ними делать.
Классические системы хранения позволяют нам накапливать информацию, предоставлять к ней доступ по запросу, обрабатывать по указанным шаблонам, не слишком быстро, не легко масштабируемо. Увеличение объёма данных для обработки неизбежно ведёт к увеличению времени в ожидании результата. Причём не линейно, а экспоненциально. Классические СУБД не справляются с Большими Данными. И становится не понятно, как этим богатством распоряжаться.
Существуют три основные проблемы для Больших Данных – как хранить, чем обрабатывать, как обрабатывать. И, конечно, самое важно – кто всё будет делать? Давайте разберёмся.
Большие данные потому и называются большими, что физически занимают очень много места на диске. Хранить их классическим способом в базах данных не удобно и не выгодно, поэтому в экосистеме открытого кода появилось решение в виде платформы Hadoop.
Hadoop представляет собой и систему хранения Hadoop Distributed File System (HDFS), и платформу обработки данных на базе разных движков, например, Map-Reduce. HDFS в рамках кластера организует программно-распределённую систему хранения, доступ к которой организуется через сервер имён (NameNode), а сами данные расположены на подчинённых серверах (DataNode).
HDFS хранит информацию, где какие данные находятся – путь, список блоков и их реплик. Уникальной HDFS делает тот факт, что сервер имён раскрывает для всех желающих расположение блоков данных на машинах, благодаря чему функцию обработки данных можно выполнять локально, не нагружая сеть процессом передачи данных с сервера хранения на сервер обработки.
Таким образом можно сэкономить время на процессе установки TCP-соединения и выполнять задачи параллельно, повышая эффективность обработки. Именно этим занимается движок Map-Reduce.
Задача обработки данных делится на две части: Map и Reduce. Первая, Map, выполняется параллельно и, в основном, локально над каждым блоком данных. Вместо того, чтобы доставлять терабайты данных к программе, сравнительно небольшая программа копируется на сервера с данными и делает с ними всё, что нужно и не требует перемешивания и перемещения данных. Вторая часть, Reduce, дополняет Map агрегирующими операциями, объединяя и группируя данные. А для оптимизации вычислений, можно использовать Spark, который позволяет хранить промежуточные результаты вычислений не на диске, а в оперативной памяти, что в разы увеличивает производительность.
Итак, есть платформа Apache Hadoop, решающая задачи хранения и реализации вычислений. Половина проблем решена, но осталась вторая половина – как формализовать вычисления, да и кто формализовывать будет? Здесь на сцене появляется Data Scientist – специалист по работе с данными. Именно на плечи этих пионеров обработки данных ложится груз ответственности по написанию логики программы-обработчика, по подготовке правильной структуры данных, которая верно будет обработана программой, и, конечно же, именно эти люди занимаются построением моделей и прогнозированием в среде Больших Данных.
К сожалению, понимание логики работы с Большими Данными пока доступно не всем, но у многих компаний есть огромное желание быть на передовой успеха (а кто владеет информацией – владеет современным миром). Для таких организаций и специалистов компания Microsoft разработала линейку обучающих курсов по работе с Большими Данными.
Первым курсом в линейке представлен 20773 «Анализ Больших Данных с помощью Microsoft R», который расскажет про инструменты обработки Больших Данных, опишет логику работы приложений для Больших Данных и покажет, как интегрировать среду обработки Больших Данных с существующей ИТ-инфраструктурой. Этот курс для разработчиков, админов SQL Server и аналитиков, глубоко разбирающихся в средствах обработки и хранения данных.
Следующий курс 20774 «Облачная аналитика Больших Данных при помощи машинного обучения в Azure». Здесь можно узнать, как без сложной ИТ-инфраструктуры обрабатывать большие данные на серверах в облаке и предоставить результаты вычислений авторизованным пользователям. Курс рассчитан на компании, пока не вложившиеся в свою дорогостоящую инфраструктуру для обработки Больших Данных, а ещё приглядывающиеся и оценивающие – надо или не надо, стоит или не стоит? Чтобы понять – нужно попробовать. И Microsoft предлагает попробовать большие данные на вкус в рамках облака Azure, объясняя в курсе 20774, как воспользоваться инструментами машинного обучения Azure для обработки Больших Данных в облаке.
Для тех, кто понял, что за Большими Данными виднеется большое будущее компании, разработан курс 20775 «Обработка данных с Microsoft HDInsight». Здесь показано, как настроить кластера Hadoop в рамках Microsoft HDInsight, как обслуживать инфраструктуру и устранять неполадки, как настраивать потоковую обработку Больших Данных и создавать интерактивные запросы, а результат визуализировать и предоставлять пользователям. Курс 20775 рассчитан на администраторов, разработчиков и архитекторов систем хранения и обработки Больших Данных.
А для пользователей, желающих ёмко, наглядно и красочно представить результаты обработки Больших Данных подготовлены курсы 20778 «Анализ данных с помощью Power BI» и 20779 «Анализ данных с помощью Excel», решающие задачи визуализации и интерактивного представления данных.
Если перед Вами стоит задача создать интерактивную и информативную экспресс-панель для анализа Больших Данных и разделить доступ к ней со многими участниками с привлечением сервера для публикации – то Вам нужен курс 20778 «Анализ данных с помощью Power BI».
Если Вы пока изучаете возможности интерактивных панелей и задачи ограничиваются предоставлением отчёта в рамках книги Excel, то стоит начать знакомство с миром обработки Больших Данных с курса 20779 «Анализ данных с помощью Excel», рассматривающего возможности настольного приложения Excel 2016 в задачах бизнес-аналитики.
А мы в свою очередь поможем Вам пройти пока не торенной тропой Больших Данных и научим успешно пользоваться передовыми технологиями работы с Большими Данными. Ждём Вас в УЦ «Эврика» на курсах по обработке Больших Данных!